


In the world of programming, efficiency, and performance are paramount. Developers are often faced with the challenge of making their applications run faster and more smoothly. Two key techniques that help achieve this are asynchronous programming and Multithreading. In this article, I will dive into these concepts and explore their implementations in Python. I won’t be covering more complex concepts and documentation details in this article as you can refer to the documentation after getting a clear idea about these concepts.
You can find all the example code in this GitHub repository : https://github.com/DahamDev/python-async-multithreading.git
Asynchronous Programming
Asynchronous programming is a programming paradigm that allows tasks to run independently of each other and not block the execution of the main program or other tasks. It is commonly used when dealing with tasks that involve waiting for external resources like network requests or file I/O. Asynchronous programming enables a single thread of execution to handle multiple tasks by allowing a task to pause and resume without blocking the entire thread.
Imagine you’re at a coffee shop. You place an order and wait for your coffee. In traditional synchronous programming, you’d stand in line, wait for your order to be taken, and then wait again for your coffee to be prepared. In an asynchronous setup, you could place your order and then continue browsing your phone or reading a book until your coffee is ready. This way, you’re not blocked from doing other things while waiting.
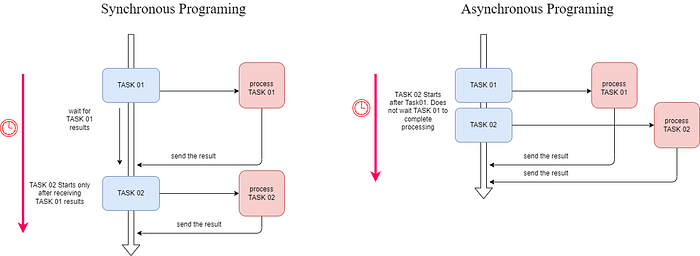
Implementing Asynchronous Programming in Python
Asynchronous programming in Python is facilitated by the asyncio library, introduced in Python 3.5. It allows you to write asynchronous code using the async and await keywords. The heart of asyncio is event loops, which manage the execution of asynchronous tasks. These tasks run concurrently and can be paused using await without blocking the entire program.
Consider a scenario where a web server needs to handle multiple incoming requests concurrently. With asyncio, the server can start processing another request while waiting for I/O operations like file reads or network requests to complete. This prevents threads from blocking and maximizes resource utilization.
You might have heard this saying: “Choose async IO when you can, and use threading when you really have to.” The reason behind this is that making code work well with multiple threads can be quite tricky and full of mistakes. Async IO, on the other hand, helps you avoid some of the tricky spots you might run into with threads.
Async IO is like a smoother road with fewer bumps when it comes to handling multiple tasks. It’s a way to manage tasks that spend a lot of time waiting, without getting tangled up in the complexities that can come with threading. So, if you have the choice, async IO can be a smoother and safer option!
A synchronous code
Imagine you’re ordering food at a restaurant, but you’re doing it the old-fashioned way — one thing at a time. You pick something, order it, wait until it’s delivered, and only then move on to the next thing. This takes a while because you’re doing each task in a sequence.
import time
def order_coffe():
print("Ordered Coffee")
time.sleep(1)
print("\\t\\t >> Received coffee")
def order_food():
print("Ordered Food")
time.sleep(5)
print("\\t\\t >> Received Food")
def order_cake():
print("Ordered Desert")
time.sleep(3)
print("\\t\\t >> Received Cake")
def main():
order_coffe()
order_food()
order_cake()
if __name__ == "__main__":
s = time.perf_counter()
main()
elapsed = time.perf_counter() - s
print(f"sync-operations executed in {elapsed:0.2f} seconds.")
Now, if you peek at the code’s results, it’s like you’re seeing a slow-motion movie. You can clearly see that each step happens one after the other. This whole process takes 9 long seconds to finish.
It’s like doing things the way we used to before modern tricks like async IO came along. Things happen in order, step by step, and that can make it take longer. But with async IO, you’re more like a speedy squirrel, getting things done all at once and saving a lot of time!
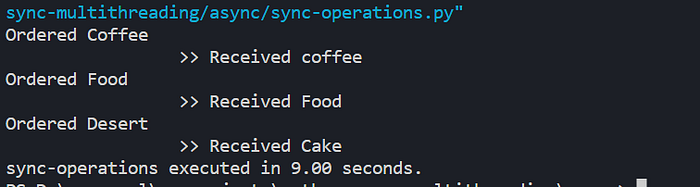
command line output of the synchronous code execution
Now let’s try to implement the same scenario using an asynchronous code.
For this implementation, I am using the Python asyncio package. and instead of using time.sleep() to sleep my code, I am using 8await asyncio.sleep(1) which implements the asynchronous behaviour of sleep function.
Do not worry about the new await and async syntaxes I have used here we will have a look at these syntaxes and underlying concepts in later sections.
import time
import asyncio
async def order_coffe():
print("Ordered Coffee")
await asyncio.sleep(1)
print("\\t\\t >> Received coffee")
async def order_food():
print("Ordered Food")
await asyncio.sleep(5)
print("\\t\\t >> Received Food")
async def order_cake():
print("Ordered Desert")
await asyncio.sleep(3)
print("\\t\\t >> Received Cake")
async def main():
await asyncio.gather(order_coffe(), order_food(), order_cake())
if __name__ == "__main__":
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"sync-operations executed in {elapsed:0.2f} seconds.")
Interesting Fact!!!!
Absolutely, it’s like a clever way of getting things done faster! Let’s break it down. Imagine you’re ordering food. In the traditional way, you’d place an order, wait for it to be prepared and delivered, and only then place the next order. This can take quite a bit of time. But with async IO, it’s like you’re a super-efficient multitasker. You place all your orders at once and don’t just sit around waiting for each order to be ready before ordering the next. Instead, you keep going, and by the time you’re done placing all your orders, the first one might already be ready!
This “order now, get it when it’s done” approach saves a lot of time. You’re not stuck twiddling your thumbs between orders. So, in the end, the whole process gets done much faster, taking only 5.02 seconds in this example. It’s a bit like ordering your tasks to be done in a smarter order and using your time more wisely. It’s a nifty trick that can make things way more interesting and quicker!
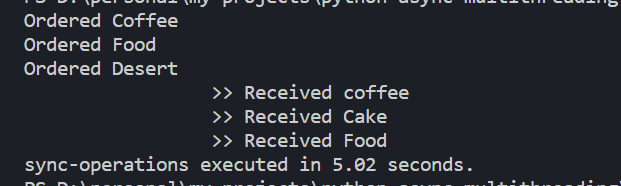
command line output of the asynchronous code execution
async keyword
The async keyword is used to define asynchronous functions. These functions can be paused and resumed while waiting for something to complete, like IO operations. By using the async keyword with all the function definitions we indicate that all our functions are asynchronous. which means our food ordering process can be resumed while waiting for the order to complete ( simulate by sleep).
await keyword
The await keyword is used inside asynchronous functions to pause the execution of the function until the awaited task (usually an asynchronous operation) is complete.
asyncio. gather
asyncio. gather is a function in the asyncio library that lets you run multiple asynchronous functions concurrently and collect their results. When you call asyncio.gather(func1(), func2(), ...), it starts executing func1, func2, etc., concurrently, and waits for all of them to finish. The gather function returns a list of "futures." A future is an object that represents the result of an asynchronous operation that is still in progress. When you await a future, you're essentially telling the program to pause until the result of that future is available. In this case, you use await asyncio.gather(...) to wait for the futures to complete.
To Sum Up
The code you provided demonstrates how to use the async and await keywords to create asynchronous functions that can be paused and resumed during IO-bound tasks. The asyncio.gather function helps you run these asynchronous functions concurrently and collect their results using futures. This approach helps make programs more efficient by efficiently using time when tasks are waiting for something to complete
Multithreading
Multithreading is a technique that enables a program to execute multiple threads concurrently within a single process. Each thread represents an independent flow of execution, allowing the program to accomplish multiple tasks at the same time. This can lead to improved responsiveness and enhanced performance, particularly in tasks that involve waiting, such as I/O operations.
Before diving into multi-threading there are a few terms we need to be familiar with.
- Process
A process is like a self-contained program that’s running on your computer. Imagine it as a person working on a task. Each process has its own memory space, resources, and code that it executes. Processes are separate from each other, which means they can’t directly access each other’s memory or resources. Each process runs independently and doesn’t interfere with the workings of other processes. For example, when you run a web browser, a music player, and a word processor, each of these is a separate process.
- Thread
A thread is like a smaller unit of a process. Think of it as a task or a job that a process can perform. Threads within the same process share the same memory space and resources, which allows them to communicate and share data more easily than processes. Threads can run concurrently within a process, which means they can work on different tasks at the same time. Each thread will have its own memory for registers and stacks. However, threads within the same process need to coordinate and manage access to shared resources to avoid conflicts. For instance, in a web browser process, there might be multiple threads handling tasks like rendering web pages, fetching data, and managing user interactions.
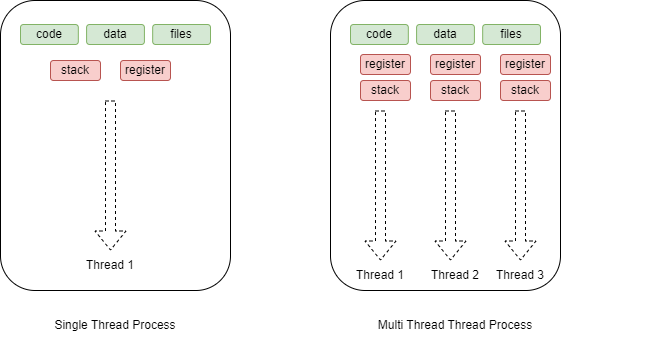
There are two ways to achieve multi-threading in Python programs.
Using the threading module
Using Python concurrent.features
python threading module provides a simple and straightforward method to implement multi-threading while concurrent.futures module provides a high-level interface for asynchronously executing functions using threads or processes. It includes the ThreadPoolExecutor and ProcessPoolExecutorclasses that manage worker threads or processes, respectively.
For instance, if you have a script that needs to download multiple files from the internet, you can use a thread pool to download them concurrently without blocking the script’s execution.
Using the Python threading module
First, we import the threading module
import threading
I have defined the download function to simulate the downloading behavior of a file. Based on the file name and the size we pass as arguments for this function, it will print the number of MBs downloaded over time.
def download(filename, size):
for i in range (0, size):
print(f"{filename} downlaoded {i} MB")
sleep(1)
Then I use threading.Thread method to create a new thread and assign them to a variable. There is an important thing to note that we need to create two arguments target and args for this method. “target” should be the process the thread should execute. In our case, it is the download method. “args”should be the arguments we need to pass to the download function. These arguments should be passed as a tuple.
Then we can use thread.start() method to run the thread.
import threading
from time import sleep
def download(filename, size):
for i in range (0, size):
print(f"{filename} downlaoded {i} MB")
sleep(1)
thread1 = threading.Thread(target=download, args=("pictures.zip", 5))
thread2 = threading.Thread(target=download, args=("musiz.zip", 10))
thread1.start()
thread2.start()
If you look at the command line output of your code you will see that download operations of musiz.zip and pictures.zip process parallel.
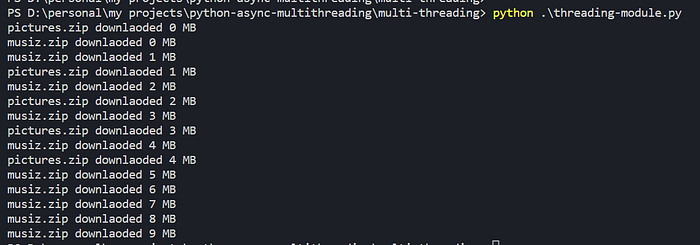
Using Python concurrent.features
In the above section, we learned how to use the threading module to write a simple multi-threading application using Python. This method is simple but prone to errors. If you do not handle these errors carefully there can be concurrency issues in your program. To solve these issues the concurrent.futures module is introduced in Python which provides a “ThreadPoolExecutor” class that makes it easy to create and manage a thread pool.
Let’s implement the same code using this module.
First, we need to create a new thread pool. Note that I have defined max_workers as 2. This means there can be up to 2 threads in this thread pool.
pool = concurrent.futures.ThreadPoolExecutor(max_workers=2)
Now when I call the pool.submit() method with my download function and its arguments as arguments of the summit function, the thread pool will start executing the download function.
import concurrent.futures
from time import sleep
def download(filename, size):
for i in range (0, size):
print(f"{filename} downlaoded {i} MB")
sleep(1)
pool = concurrent.futures.ThreadPoolExecutor(max_workers=2)
pool.submit(download, "pictures.zip", 5)
pool.submit(download, "musiz.zip", 10)
pool.shutdown(wait=True)
If you observe the output of the code you will notice that picture and music download processes happen separately in two different threads.
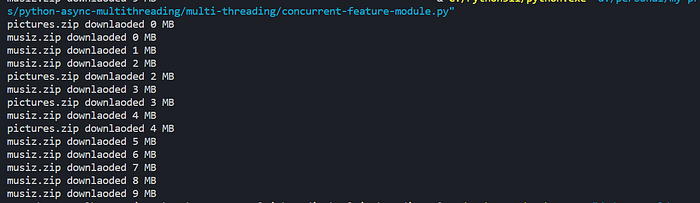
What if I change the max_workers to 1?
If we change max_workers to 1, the thread pool will have only one thread and it won’t be able to handle two downloads parallel using two threads. First, it will finish the picture download process and then start the music download process.
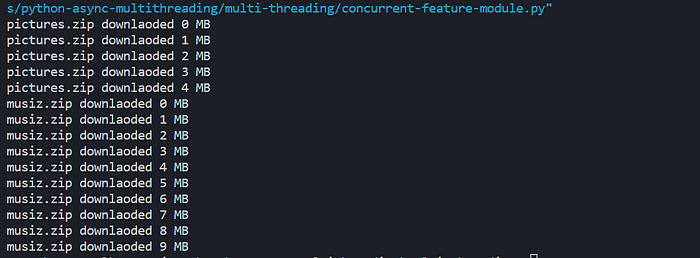
Conclusion
In the world of programming, efficiency is key. Asynchronous programming and concurrency are powerful techniques that allow developers to optimize their applications for better performance. While asynchronous programming focuses on non-blocking I/O operations and event-driven tasks, concurrency enables multiple tasks to appear as if they are running simultaneously. Python’s libraries like asyncio and concurrent.futures make it easier than ever to implement these techniques and harness their benefits. By understanding and applying these concepts, developers can create more responsive and efficient applications that meet the demands of modern computing.
You can find all the example code in this GitHub repository : https://github.com/DahamDev/python-async-multithreading.git
References